Snowflake Data Profiler
A data profiler runs an analysis on a sample piece of data against selected parameters like completeness, validity, character count and so on. This provides statistics of the data on those parameters.
-
Add the data quality stage after the Data Lake stage. Add a Data Profiler node. Connect the node to and from the data lake.

-
Click the Data Profiler node and then click Create Job.

-
Provide the following information to create the data profiler job:
 Job Name
Job Name
-
Job Name - provide a name for the data profiler job.
-
Node Rerun Attempts - the number of times the job is rerun in case of failure. The default setting is done at the pipeline level.
-
Fault tolerance - Select the behaviour of the pipeline upon failure of a node. The options are:
-
Default - Subsequent nodes should be placed in a pending state, and the overall pipeline should show a failed status.
-
Skip on Failure - The descendant nodes should stop and skip execution.
-
Proceed on Failure - The descendant nodes should continue their normal operation on failure.
-
Click Next.
Source

-
Datastore - This is automatically selected depending on the configured datastore.
-
Database - This is automatically selected depending on the configured datastore.
-
Schema - Select the schema as per your requirement.
-
Table - Select a table and click Add.
-
Tables Added - Click the arrow to view the columns of the added table. You can select only one table at a time. To select another table, delete the existing table and then select another one.
-
Records from File - Specify the records that you want to use for data profiling, either as a percentage or as number of records.
-
Percentage - Specify the percentage of data to be used for data profiling.
-
Number of records - Specify the number of records to be used for data profiling.
-
-
Seed Value - Specify the seed value. This is the number used to initialize the random number generator that ensures repeatability and consistency during data generation for data quality testing.
-
Profiler Constraints - Select the constraints that you want to run on the selected data for data profiling. Choose from the following:
-
All - Select all the constraints to run on the selected data in the data profiler job.
-
Completeness - Checks whether the data fulfills the expectation of comprehensiveness. For example if customer name is asked, then whether first name and last name are present for all records. If either of the two is missing the record is marked as incomplete.
-
Type - Returns the data type of the column such as boolean, fraction, or integer.
-
Validity - Checks whether data is available in the prescribed format. For example, in case of date of birth, if the specified format is mm:dd:yy and data is provided in dd:mm:yy format, then the record is invalid.
-
Count - Checks the count of distinct, filled, or null values.
-
Character Count - Calculates the number of records that have numbers, numbers only, letters only, letters and numbers, and special characters.
-
Statistical Value- Describes the distribution of numeric data across various statistical measures like minimum, maximum, mean, and standard deviation.
-
Recommendation - Provides suggestions or recommendations based on the profiling results, indicating potential improvements or actions.
-
-
Define Null Values - Select the values from the dropdown to define which values should be treated as null. These values are excluded during processing. You can either select one from the dropdown or add a custom value.
Select from the following options:
-
NULL
-
NA
-
N/A
-
#NA
-
#N/A
-
EMPTY
-
null
-
Target

-
Datastore - The datastore that is preselected is populated.
-
Database - The database that is preselected is populated.
-
Schema - The schema that is preselected is populated.
-
Table - Provide a name for the table in which you want the profiler results to be stored. Refer to the Snowflake recommendation for the naming convention of the table. Identifiers Syntax
-
-
The Data Profiler job is created. Click the Data Profiler node and click Start to initiate the job run.

The status of the job can be one of the following:
-
Running
-
Completed
-
Failed
-
-
Once the job is complete, click the Profiler Result tab and click View Profiler Results.

On the Data Profiler Output screen, you can do the following:
-
View the results of the Data Profiler job.
-
Download the results in a CSV file. Click
 .
. -
Provide the pattern for validation and click Validate.

Note:
The pipeline must be in Edit mode for the Validate button to be enabled.
-
-
Specify the pattern for validation and click Validate to validate the data in the selected columns based on the provided pattern. You see a success message: Validation rules updated successfully.
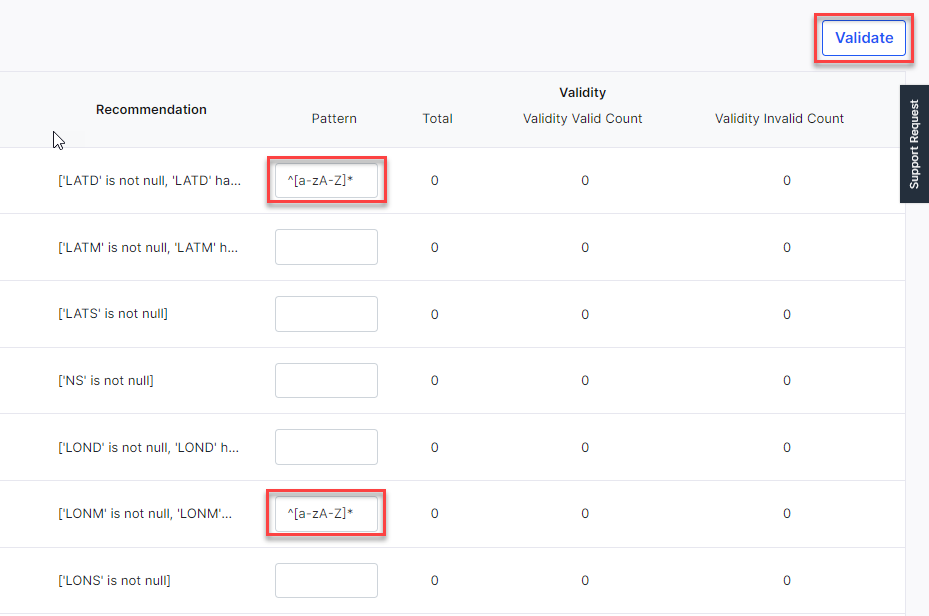
-
You can run the validation job in the following ways:
-
Publish the changes. Click Start to run the validation job.
-
Click the Data Profiler node. Click Start to run the validation job.
-
Once the job is complete you can view the results of the validation job under the Validated Profiler Result tab. You can download the results in the form of a CSV file.
| What's next? Snowflake Data Analyzer |